Google 은 2022년 8월 24일에 스프레드시트를 위한 새로운 함수를 발표했습니다 .
가장 큰 소식은 Named 함수라는 새로운 기능 입니다. Named 함수 를 사용하면 일반 스프레드시트 함수로 빌드된 고유한 맞춤 수식을 저장하고 이름을 지정한 다음 다른 Google 스프레드시트 파일에서 재사용할 수 있습니다. 공식을 재사용할 수 있도록 하기 위한 거대한 단계입니다.
참고: 이러한 기능은 점진적으로 출시되고 있으므로 스프레드시트에서 해당 기능에 액세스하는 데 최대 15일이 소요될 수 있습니다.
Named 함수 와 9개의 새로운 함수들을 살펴보겠습니다.
1. Named 함수
Named 함수 를 사용하는 이유
조직의 스프레드시트 전문가가 유용한 기능 모음을 생성한다고 상상할 수 있습니다. 그러면 누구나 원할 때마다 이러한 사용자 정의 공식을 가져와 사용할 수 있습니다. 그들은 내부에서 어떻게 작동하는지 이해할 필요조차 없습니다.
예를 들어 복잡한 공식을 사용하여 비즈니스에서 중요한 재무 지표를 계산한다고 가정합니다. 누구나 보고 싶어하지만 대부분의 사용자가 만들기가 너무 어렵고 오류가 발생하기 쉽습니다. Named 함수 를 사용하면 SUM 함수를 사용하는 것만큼 쉽습니다.
그럼 어떻게 만들까요?
Google 스프레드시트의 Named 함수 를 사용하면 내장된 모든 함수를 사용하여 나만의 맞춤 수식을 저장하고 이름을 지정할 수 있습니다.
사용자들이 만든 그 복잡한 재무 공식은… 물론, =BENFINANCE(input1,input2,…)라는 이름의 함수로 바꾸고 대신 사용하십시오!
그리고 무엇보다도 다른 Google 시트 파일에서 이러한 Named 함수 를 재사용할 수 있습니다.
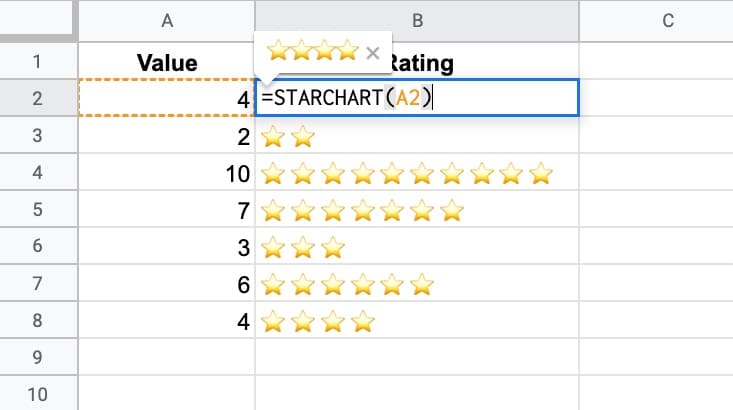
다음은 미니 별표 평점 차트를 그리고 다른 스프레드시트에서 재사용할 수 있는 STARCHAR라는 Named 함수 의 예입니다.
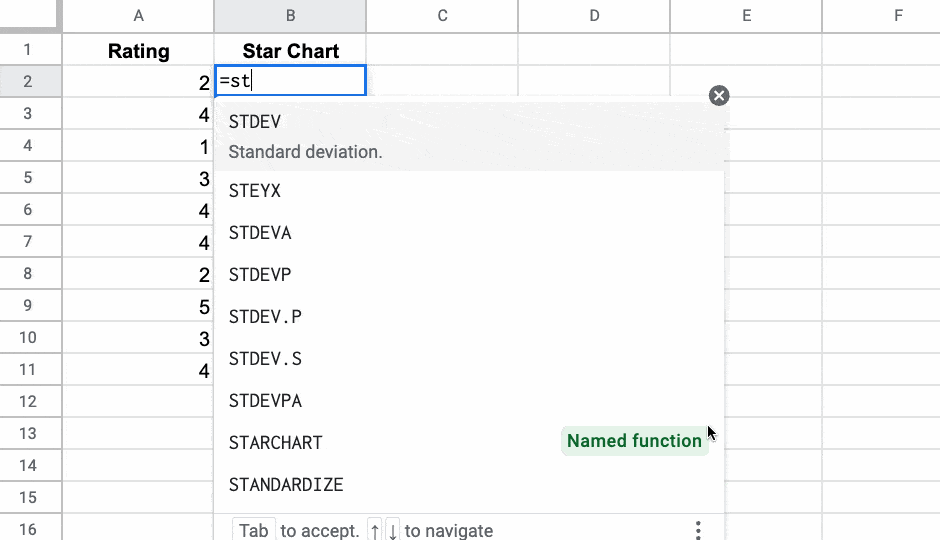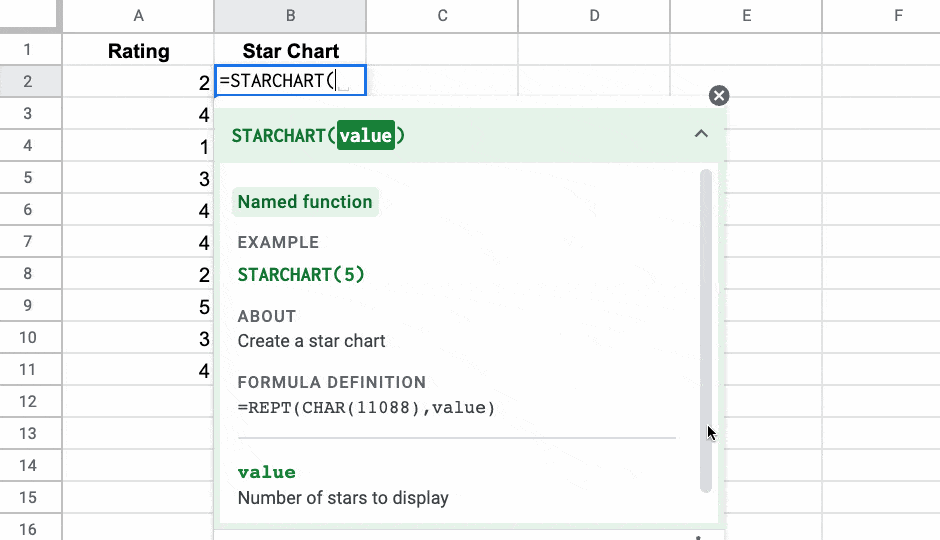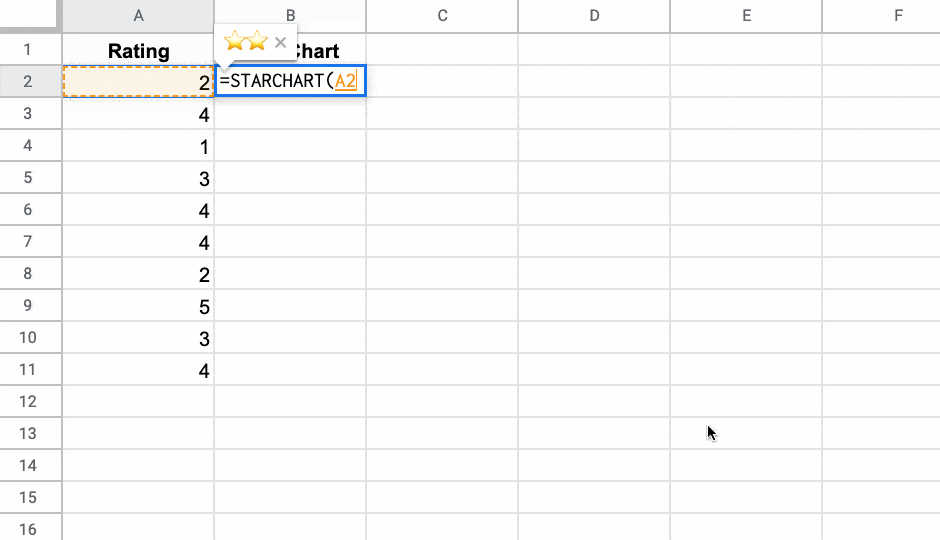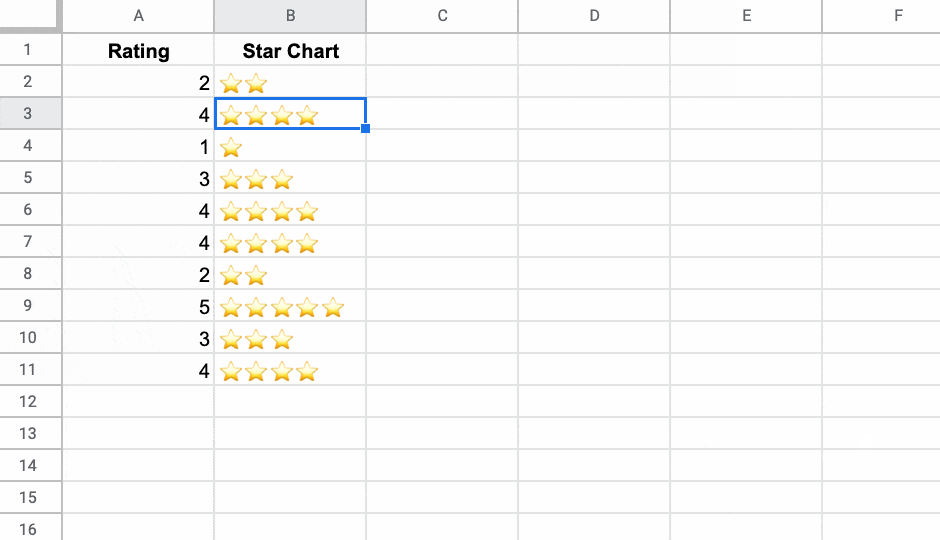
Named 함수 에 대해 자세히 알아보도록 하겠습니다.
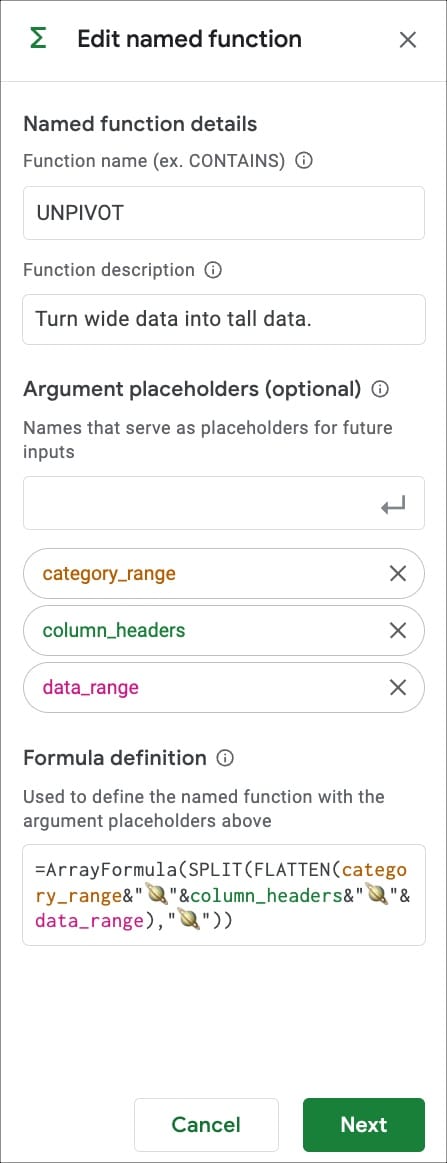
여기에서는 UNPIVOT이라는 이름의 함수를 사용하여 넓은 데이터를 tall형 형식으로 변환합니다.
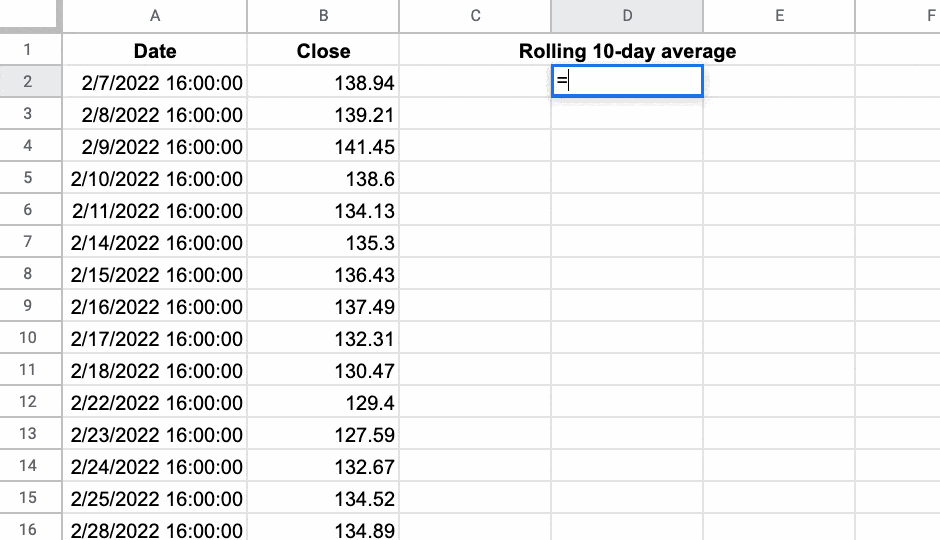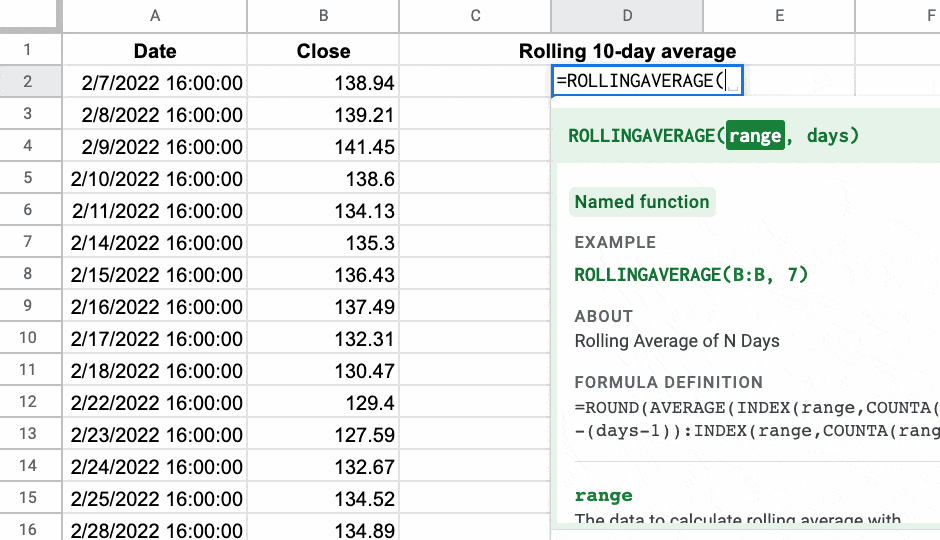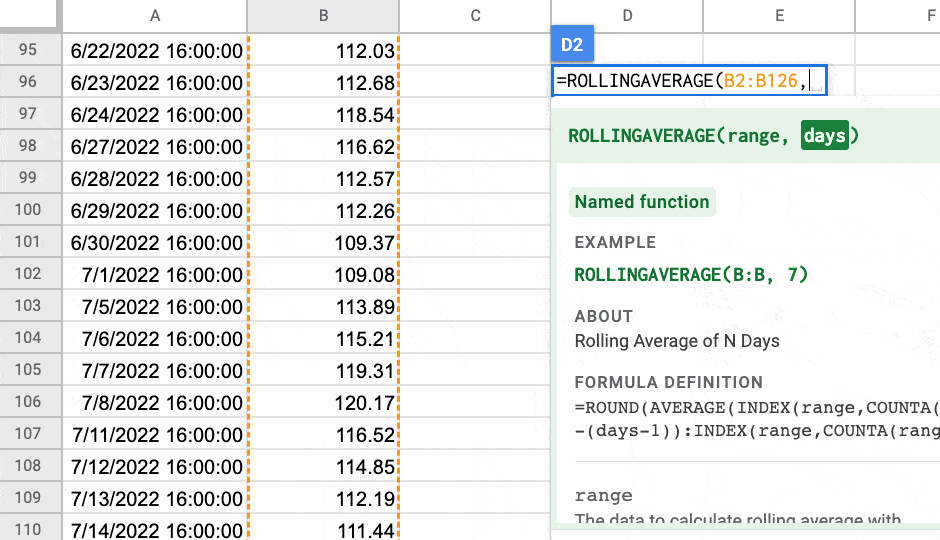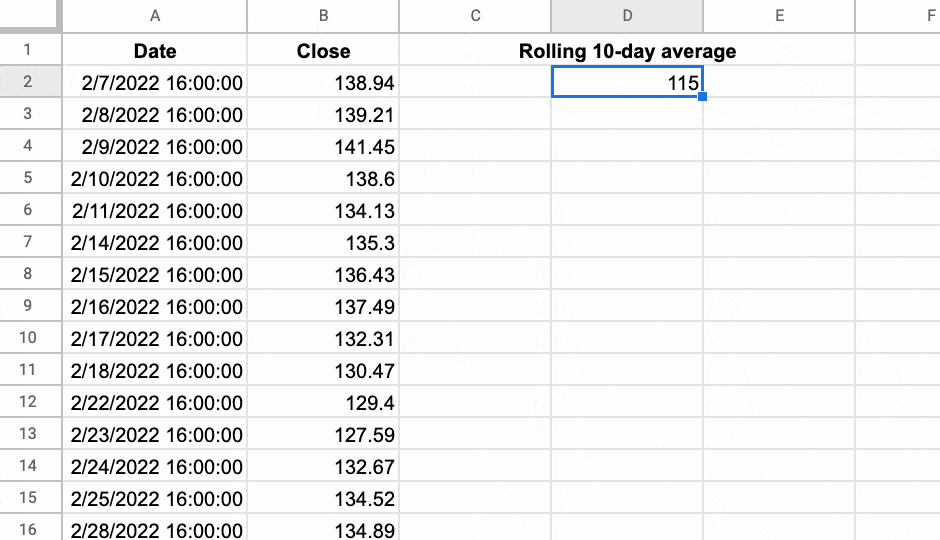
마지막 예로, 여기에서 내가 만든 Named 함수 를 사용하여 내 데이터의 롤링 10일 평균을 계산하고 있습니다.
Named 함수 는 몇 년 만에 가장 큰 Google 스프레드시트 업데이트로, Connected Sheets 이후 가장 큰 업데이트 입니다.
Named 함수 가 얼마나 유용한지 과장하기는 어렵습니다. Google 스프레드시트 팬이라면 산타가 일찍 와서 가장 큰 크리스마스 선물을 주는 것과 같습니다.
참고: 스프레드시트에 Named 함수 가 표시되기까지 8월 24일부터 최대 15일이 소요될 수 있습니다.
Google 스프레드시트에서 Named 함수 를 만드는 방법
위의 별표 예를 살펴보겠습니다.
내 Google 시트에서 별표 평점을 추가하는 수식을 만듭니다. 고객 서비스 팀이 사용할 수 있는 유용한 공식이지만 일부 사람들이 사용하기에는 너무 복잡합니다. 그러나 명명된 기능으로 전환하면 조직 내 모든 사람이 일반 기능처럼 사용할 수 있습니다.
먼저 Sheet에 Named 함수 를 만들어야 합니다.
Named 함수 만들기
Named 함수 로 변환하기 전에 올바르게 작동하는지 확인하기 위해 먼저 일반 수식을 만드는 것이 좋습니다.
1 단계
시작하려면 CHAR 함수 와 REPT 함수 를 사용하여 별 공식을 만듭니다 .
=REPT(CHAR(11088),A2)
2 단계
이 기능을 마우스 오른쪽 버튼으로 클릭하고 다음을 선택합니다.
더 많은 셀 작업 보기 > Named 함수 정의

또는 메뉴로 이동:
데이터 > Named 함수

3단계
사이드바 창에서 다음을 선택합니다. 새 기능 추가
4단계
다음 화면에서 Named 함수 를 생성합니다.
시작하려면 새 기능의 이름을 입력하십시오(예: STARCHAR).
함수 이름에는 공백이 허용되지 않으며 텍스트는 함수 이름의 표준 규칙인 대문자로 기본 설정됩니다.
5단계
다음으로, 새로 Named 함수 가 수행할 작업에 대한 설명을 추가합니다. 이 예에서 “별표 기호가 지정된 횟수만큼 반복됨”이라고 가정해 보겠습니다.
6단계
Named 함수 와 일반 함수의 한 가지 큰 차이점은 셀이나 범위에 대한 참조 대신 입력으로 자리 표시자를 수식에 넣는 것입니다.
이 단계에서는 Named 함수 에 사용하려는 입력 변수를 알려줍니다. 이해하기 쉬운 경우 7단계의 함수에서 직접 정의할 수도 있습니다. 따라서 이 단계는 선택 사항입니다.
SUM 함수를 잠시 생각해 보십시오. 사용할 때 합산한 값 범위를 제공합니다. 쉽죠?
여기도 같은 거래.
이 별표 예에서는 함수에 단일 값을 입력으로 제공합니다.
따라서 value 라는 인수 자리 표시자를 추가하십시오.
7단계
마지막 상자에서 등호를 포함하여 시트의 수식을 추가합니다(아직 표시되지 않은 경우).
Named 함수 편집기는 참조(예: A2)를 자리 표시자로 바꾸라는 메시지를 표시합니다.
제안된 옵션이나 6단계에서 만든 옵션을 사용하거나 여기에 새 자리 표시자 이름을 입력합니다.
Named 함수 편집기는 참조의 모든 항목(예: A2)을 자리 표시자 이름으로 바꿉니다.
이제 편집기 창은 다음과 같습니다.

계속하려면 다음을 클릭하십시오.
8단계
마지막 단계는 자리 표시자 값에 대한 선택적 세부 정보를 제공하는 것입니다. 사용자가 이 Named 함수 를 더 쉽게 사용할 수 있도록 설명과 예제 값을 제공합니다.
“표시할 별 수” 값에 대한 설명을 추가합니다.
예제 값 5를 추가합니다.
업데이트를 클릭하여 완료합니다.
그리고 짜잔! 첫 번째 Named 함수 를 만들었습니다.
이제 다음을 입력하여 이 시트에서 이 기능을 즉시 사용할 수 있습니다.
=STARCHART(A2)
(원하지 않는 경우 A2 셀에 원래 수식을 유지할 필요가 없습니다.)
Named 함수 가져오기 및 사용
Named 함수 가 생성되면 다른 시트로 가져와서 사용할 수 있습니다.

이것이 바로 이 새로운 기능의 마법입니다. 재사용성을 향한 큰 진전입니다. 몇 년 동안 유용한 기능 갤러리를 저장할 수 있기를 바랐는데 이제는 가능합니다.
이제 Named 함수 를 가져오는 방법을 살펴보겠습니다.
1 단계
브라우저에 sheet.new를 입력하여 새로운 Google 시트를 엽니다.
2 단계
메뉴로 이동: 데이터 > Named 함수
3단계
가져오기 기능 선택
4단계
팝업 파일 선택기에서 위의 1 – 9단계에서 Named 함수 를 생성한 시트를 선택합니다.
5단계
올바른 Google 시트 파일을 선택했다고 가정하면 Named 함수 가져오기 선택기가 표시되어야 합니다.
여기에서 가져오려는 Named 함수 를 선택합니다.
확인란을 선택하고 가져오기를 누르십시오.
6단계
다른 일반 함수처럼 Named 함수 를 사용하십시오!
Named 함수 는 어떻게 작동합니까?
Named 함수 는 본질적으로 LAMBDA 함수 위에 있는 GUI(그래픽 사용자 인터페이스) 래퍼입니다.
LAMBDA 함수를 사용하면 자리 표시자를 입력으로 사용하여 사용자 정의 함수를 생성할 수 있습니다.
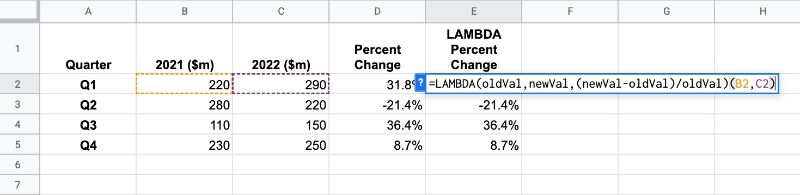
예를 들어, 이 함수는 B2와 B3 셀의 값 사이의 백분율 변화를 계산합니다.
=LAMBDA(old,new,TO_PERCENT((new-old)/old))(B2,C2)
LAMBDA 함수가 Named 함수 와 동일한 인수 및 함수 정의로 자리 표시자를 취하는 방법에 주목하십시오.
그러나 이를 수행하기 위해 전용 Named 함수 를 만들면 사용하기가 훨씬 쉽습니다.
=PERCENTCHANGE(B2,C2)
기타 Named 함수 의 예
두 가지 유용한 예인 unpivot 및 롤링 평균을 더 살펴보겠습니다.
이 게시물의 시작 부분에 있는 두 개의 GIF는 작동 중인 모습을 보여줍니다.
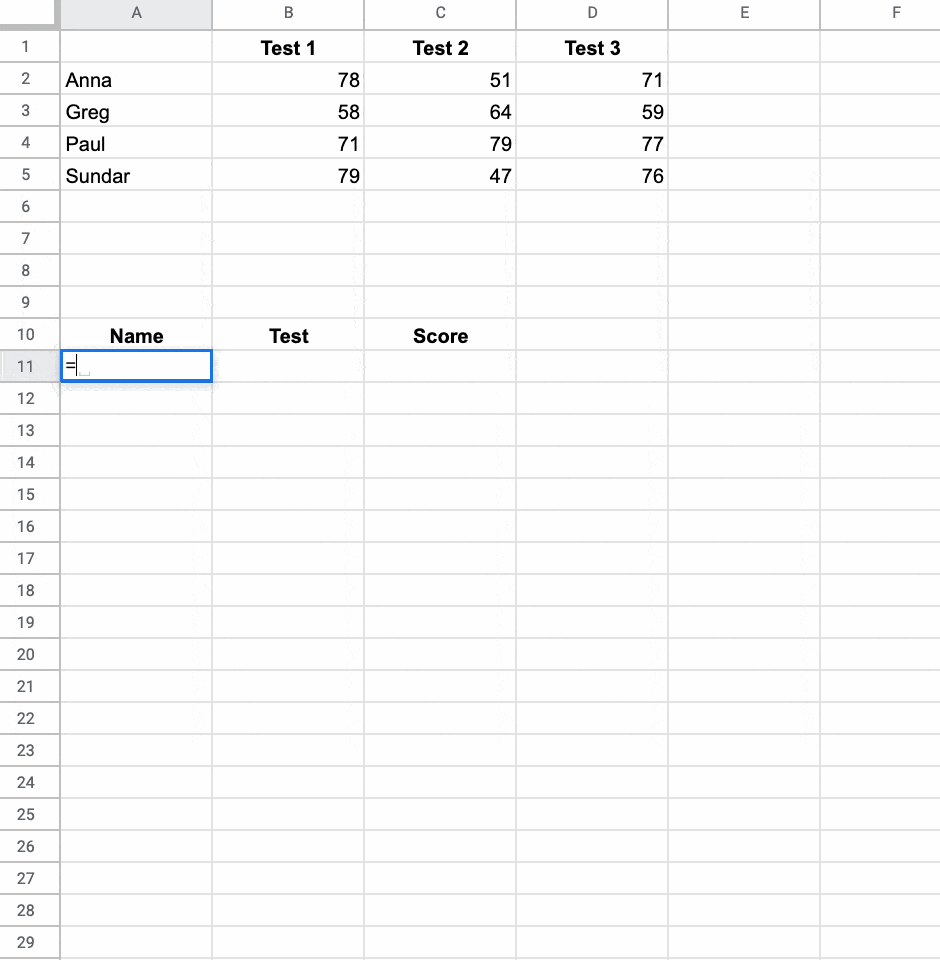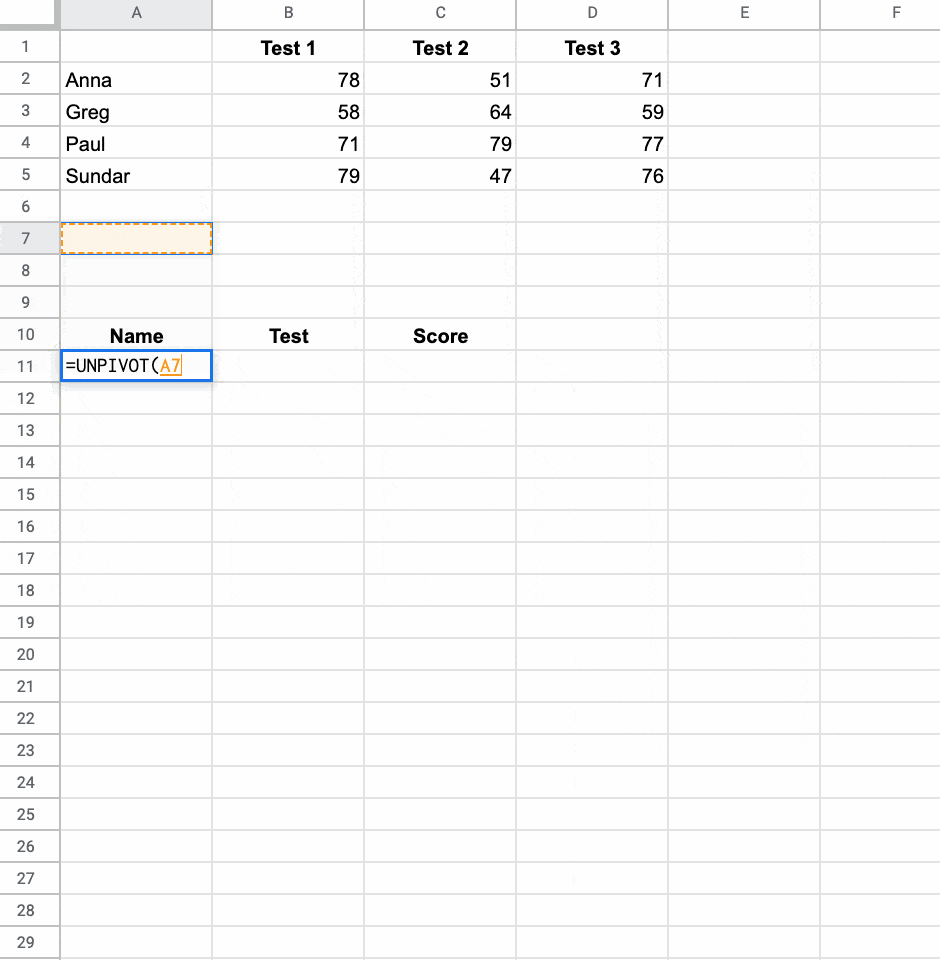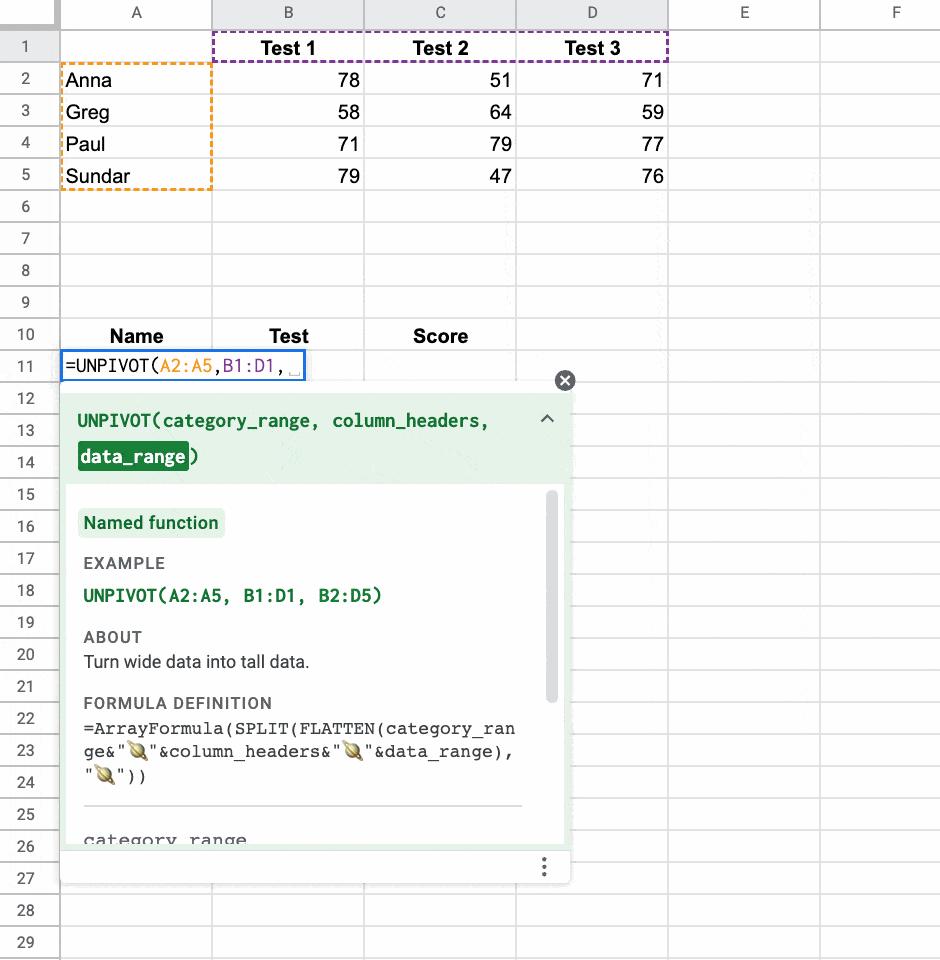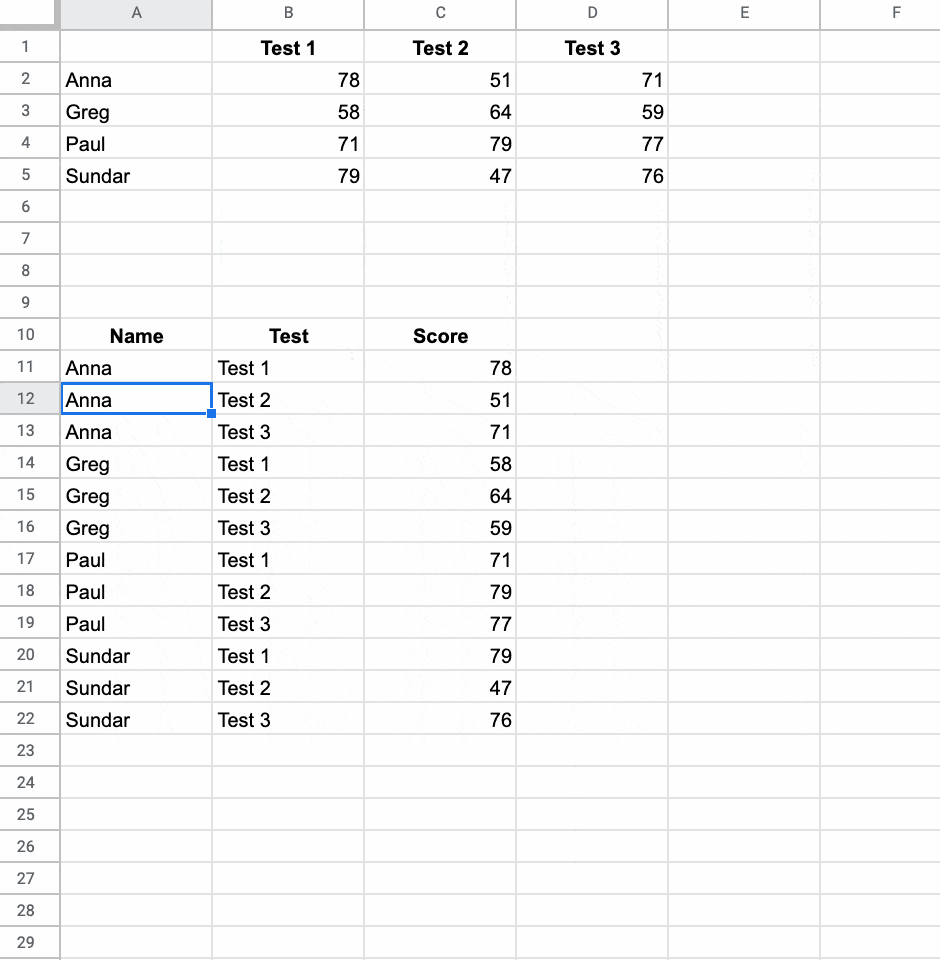
피벗 해제 예
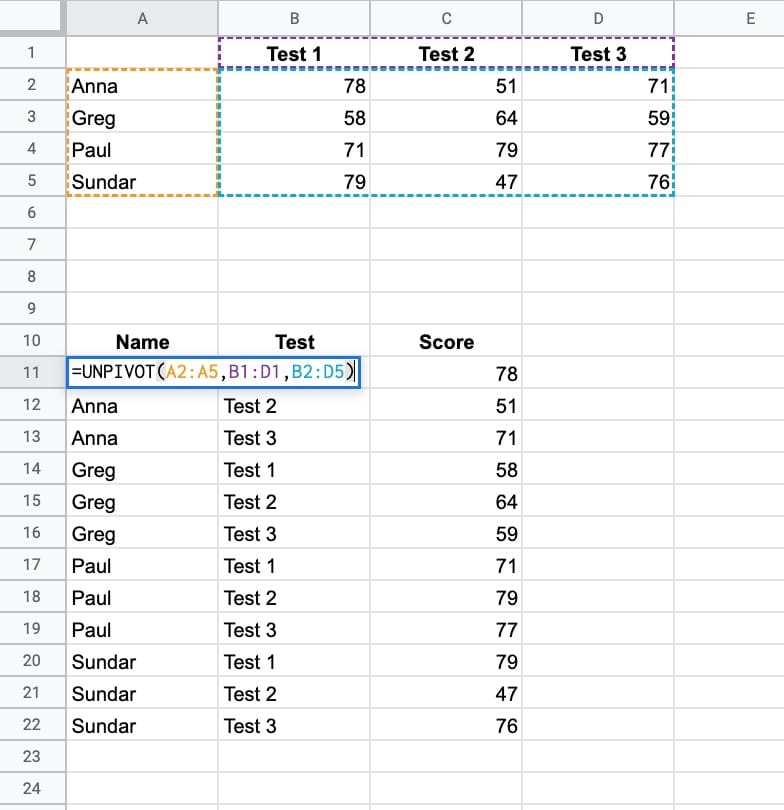
스프레드시트에서 데이터에 대한 두 가지 방향이 있습니다. 와이드 데이터 또는 긴 데이터입니다.
와이드 데이터는 열 헤더가 시리즈(예: Q1, Q2, Q3, Q4)이고 테이블이 와이드인 경우입니다. 차트에 사용됩니다.
대조적으로, tall형 데이터에는 해당 행이 Q1, Q2 등인지 여부를 기록하는 “Quarter”라는 단일 열이 있습니다. 이는 넓은 데이터보다 행이 많지만 일반적으로 열은 적습니다. 데이터베이스가 데이터를 저장하는 방식입니다.
긴 데이터에서 넓은 데이터로 이동하려면 피벗 테이블 을 사용하며 매우 쉽습니다.
그러나 넓은 곳에서 높은 곳으로 가는 것은 훨씬 더 어렵습니다. 복잡한 unpivot 공식을 사용해야 합니다( unpivot 공식 세부 정보 참조 ).
=ArrayFormula(SPLIT(FLATTEN(A2:A5&”🪐”&B1:D1&”🪐”&B2:D5),”🪐”))
고맙게도 이것을 Named 함수 로 변환한 다음 대신 사용할 수 있습니다.
=UNPIVOT(A2:A5,B1:D1,B2:D5)
훨씬 쉽게!
그리고 Unpivot이라는 이름의 함수를 정의하는 방법은 다음과 같습니다.
이동 평균 예
이동 평균을 계산하는 공식은 다소 복잡하므로 Named 함수 에 대한 훌륭한 후보입니다. 또한 날짜 수를 설정하는 인수를 추가할 수 있으므로 3일, 10일, 30일 등이 될 수 있습니다.
Named 함수 는 다음과 같습니다.
=ROLLINGAVERAGE(B2:B126,10)
이 예에서 볼 수 있듯이:

그리고 Named 함수 의 정의는 다음과 같습니다.

Named 함수 템플릿
자유롭게 사본을 만드십시오: 파일 > 사본 만들기…
템플릿에 액세스할 수 없다면 조직의 Google Workspace 설정 때문일 수 있습니다.
이 경우 링크를 마우스 오른쪽 버튼으로 클릭하여 시크릿 창에서 열어 보십시오.
Named 함수 s에 대한 Google 설명서 도 참조하세요 .
요약
이름이 지정된 함수가 스프레드시트의 재사용성에 얼마나 큰 영향을 미치는지 과소평가하기는 어렵습니다. 사람들이 이 기능을 사용하는 것을 보고 앞으로 몇 년 동안 더 발전하는 것을 보게 되어 매우 기쁩니다.
또한 Google 스프레드시트에 도입된 다른 9가지 새로운 기능으로 사람들이 어떤 작업을 하는지 매우 기대됩니다!
2. LAMBDA 함수
Google 스프레드시트의 LAMBDA 함수는 일반적인 A1 유형 셀 또는 범위 참조 대신 자리 표시자 입력이 있는 맞춤 함수를 만듭니다.
LAMBDA 함수의 주요 사용 사례는 MAP, REDUCE, SCAN, MAKEARRAY, BYCOL 및 BYROW와 같은 다른 새로운 람다 도우미 함수로 작업하는 것입니다.
LAMBDA 함수는 위에서 본 Named 함수 s의 기본 기술이기도 합니다.
다음은 백분율 변화를 계산하는 LAMBDA 함수의 예입니다.
그러나 이 경우에는 이 람다 함수를 명시적으로 만드는 것보다 PERCENTCHANGE라는 Named 함수 를 만드는 것이 좋습니다.
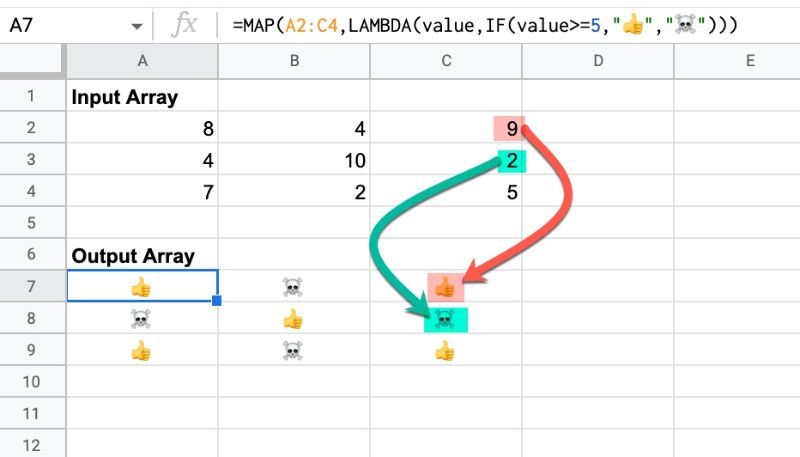
3. MAP 함수
Google 스프레드시트의 MAP 함수는 입력 범위에서 데이터 배열을 생성합니다. 여기서 각 값은 맞춤 LAMBDA 함수를 기반으로 새 값에 “매핑”됩니다.
프로그래밍의 MAP 함수와 동일한 아이디어로, 데이터 배열을 반복하고 배열의 각 요소로 작업을 수행하는 방법입니다.
MAP 함수가 작동하는 방식은 다음과 같습니다. IF 함수 를 람다 식으로 사용하여 값을 이모티콘으로 어리석게 변환하는 방법을 보여줍니다.
4. REDUCE 함수
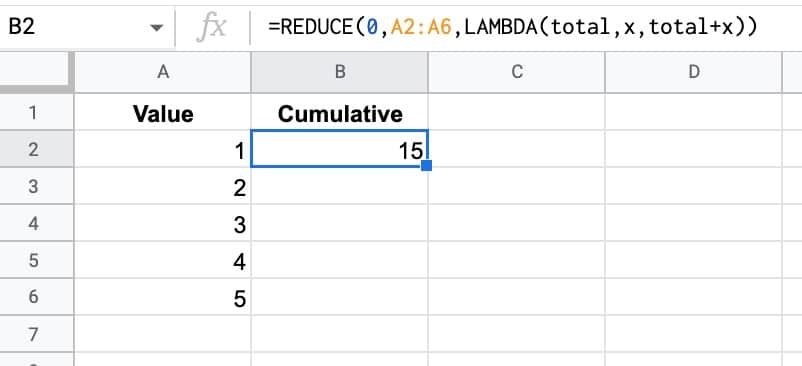
Google 스프레드시트의 REDUCE 함수는 MAP 함수와 같은 배열에서 작동합니다. 배열의 각 요소에 사용자 정의 LAMBDA 함수를 적용하여 해당 배열 입력을 단일 누적 값으로 바꿉니다. 즉, 배열을 단일 값으로 줄입니다.
예를 들어, 이 간단한 REDUCE 함수는 누적 합계를 계산합니다(예, SUM 함수를 사용하는 것이 더 쉽지만 이 감소 예제는 설명을 위한 것입니다).
5. MAKEARRAY 함수
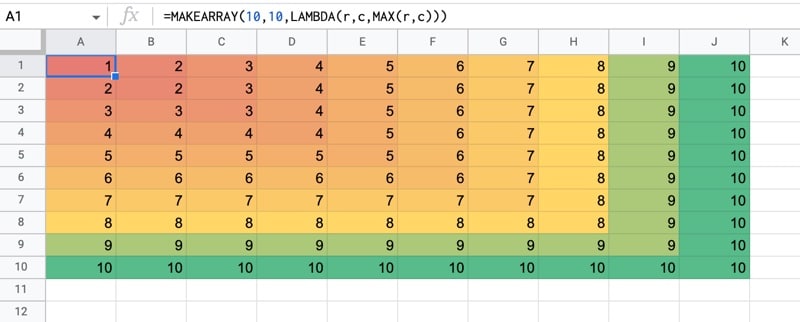
Google 스프레드시트의 MAKEARRAY 함수는 맞춤 람다 함수로 계산된 각 값을 사용하여 지정된 크기의 배열을 생성합니다.
SEQUENCE 또는 RANDARRAY 함수와 비슷하지만 이 경우 람다 함수가 배열의 각 값에 적용되므로 더 복잡한 배열을 생성할 수 있습니다.
람바 함수는 각 값의 행 및 열 인덱스에 액세스할 수 있습니다.
여기에서 람다는 행 및 열 인덱스의 최대값을 평가한 다음 여기에 히트 맵 을 추가했습니다.
6. SCAN 함수
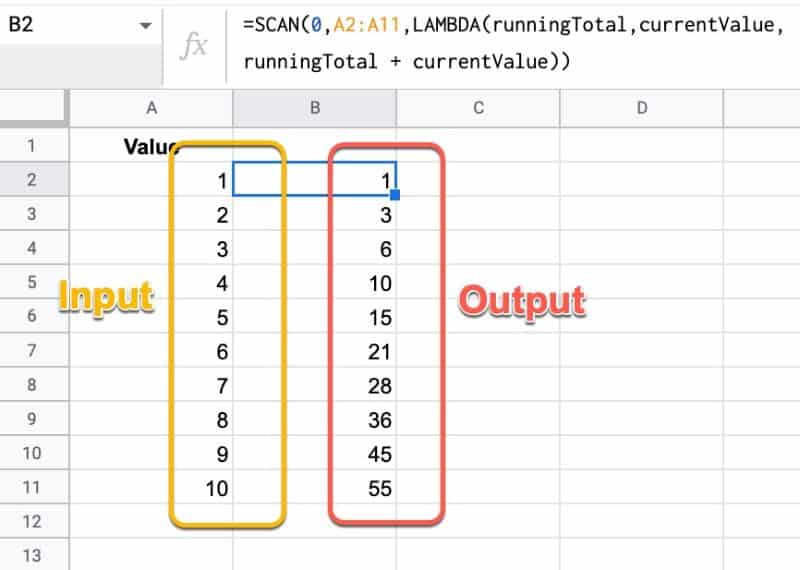
Google Sheets의 SCAN 함수는 행 단위로 이동하면서 각 값에 LAMBDA 함수를 적용하여 배열을 스캔합니다. 출력은 각 단계에서 얻은 중간 값의 배열입니다.
다음과 같이 데이터의 누계를 생성하는 가장 확실한 애플리케이션:
7. BYROW 함수
Google 스프레드시트의 BYROW 함수는 배열 또는 범위에서 작동하며 각 행을 단일 값으로 그룹화하여 생성된 새 열 배열을 반환합니다.
각 행의 값은 해당 행에 람다 함수를 적용하여 얻습니다.
예를 들어, 단일 BYROW 공식을 사용하여 입력 배열에 있는 세 행 모두의 평균 점수를 계산할 수 있습니다.

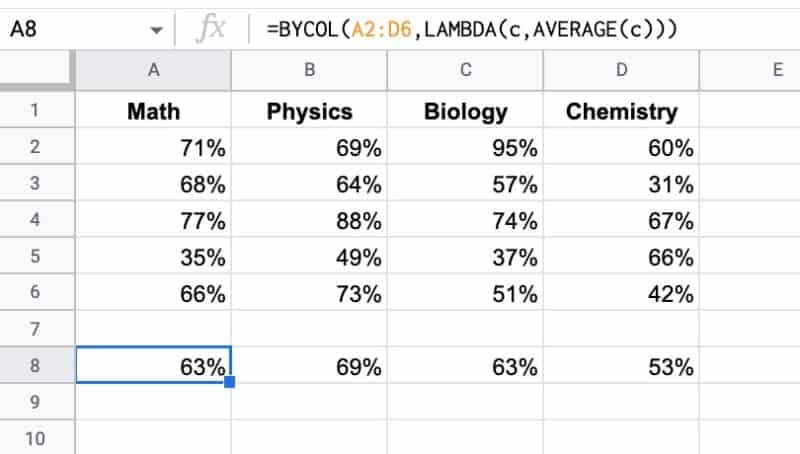
8. BYCOL 함수
BYCOL 함수는 BYROW 함수와 같은 방식으로 작동하지만 각 열을 단일 값으로 그룹화하고 새 행 배열을 반환합니다.
이 예에서 BYCOL 수식은 평균 값 행을 출력합니다.
9. XLOOKUP 함수
예! 이제 Google 스프레드시트에 멋진 XLOOKUP 기능이 있습니다!!
VLOOKUP 기능 의 보다 강력하고 유연한 버전입니다 . INDEX/MATCH 조합 공식과 몇 가지 유사한 기능을 공유합니다.
XLOOKUP은 왼쪽에서 아래에서 위로 조회할 수 있으며 정말 큰 데이터 세트로 작업하는 경우 이진 검색을 사용할 수도 있습니다.
다음은 왼쪽 조회를 수행하는 XLOOKUP의 예입니다.

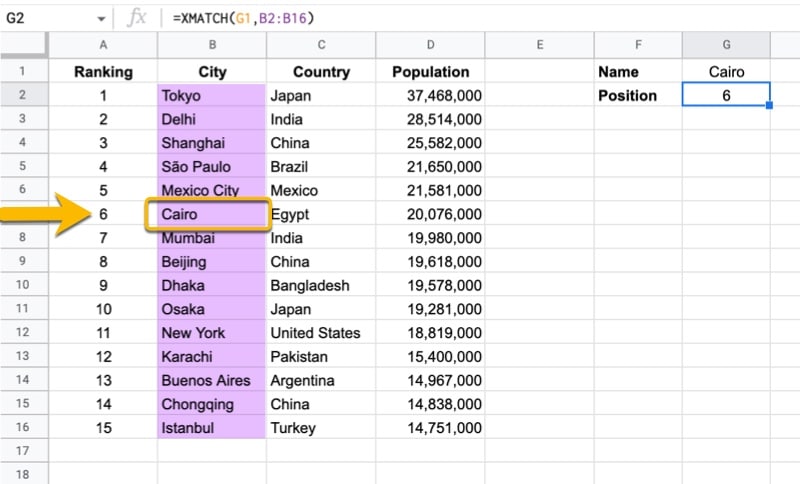
10. XMATCH 함수
마지막으로 MATCH 기능의 보다 강력하고 유연한 버전인 XMATCH 기능이 있습니다.
일반 MATCH 기능보다 더 많은 일치 모드와 검색 옵션이 있습니다.
다음은 간단한 XMATCH 예입니다.
참고: 위 내용은 8월24일자 영문 BenCollins 사이트에서 블로깅 된 것을 번역한 것입니다.

Comments are closed.